Frameworks: The cause of and solution to all your problems.
When new frameworks come out, people can really jump on the “kool-aid” train. I have had many developers and managers tout the greatness of a new framework. It’s solves many of our problems! It’s super simple! It’s really fast! Look at how beautiful and clean the code is! OMG I’M GOING TO CRY IS IS SO AWESOME!
I don’t want to get down on passionate programmers. I’ll take a passionate person over a non-plussed developer any day. Besides, all developers work in imperfect environments. We also tend to be very particular about development. When we work on a problem and there is no “thing” to truly complete it well, we typically have to work with little imperfections that bother us. After months or even years of work it’s a total relief to find an “amazing” framework that does “scratch that itch.” It’s a joyous moment in our technical, nuanced world.
So this new framework is shared with other developers. And they didn’t feel the pain with the current implementation. They don’t feel the need to abandon with no regard to this new panacea. And then when they see the syntax of the new “thing”, it doesn’t look so nice. In fact, it looks rather bothersome the way that they pass the state over to computation thing.
The better that a framework is, the more that it typically does. Most frameworks allow us to remove all of the boilerplate code and get down the the unique part of your project. And the more that it does, the less you really know what it is doing. But that’s ok! This thing is AMAZING!
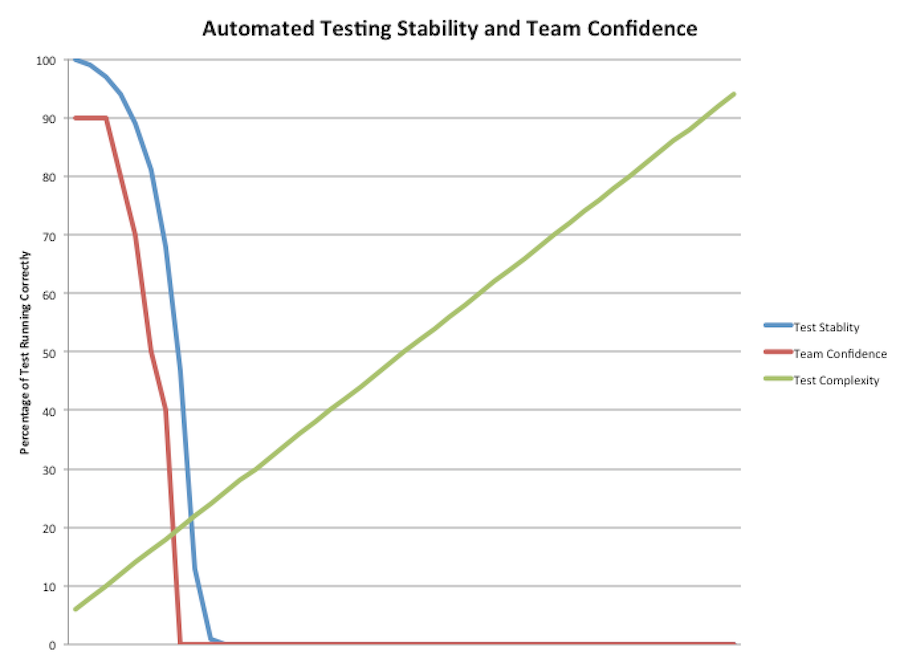
Why testing here matters
Testing a framework is important because we are going to need to use it. Plus since it is so awesome, it is going to be the underlying part of what we do. Maybe your business is selling shower curtain rings. Now you want to do it online and this “Ruby on Rails” framework is going to allow you to do it. The rails framework is going to underpin everything. Sooo… it should work properly.
The second you start working with a framework, you are doing integration coding. Your unit tests will become less and less useful. You will find yourself mocking everything. You might try to create the thinnest possible integration layer. Maybe you even venture into the black magic of partial mocks. Any way you slice it, you have a little code sitting on a small mountain of someone else’s work.
The ideal situation is a framework that shows you how to write integration tests. You need to be able to quickly setup a portion of the framework with your extensions and verify the output. Ideally, this starts up quickly ( < 100ms ) and gives you the verification that that your use of the system provides the expected output.
I’ll give you an example. In the Java world, there are two popular web MVC frameworks: SpringMVC and Jersey. These two frameworks solve the problem of handling REST calls. They allow your map rest calls to a function and translate the outputs to a web format (JSON/HTML…). I’m not going to go into the merits of either except for testing. Here is the code below for a test that accepts a GET call for a user and returns a user JSON object (translated from a POJO).
The Jersey implementation:
public class SimpleResource {
@GET
@Path("/get/things")
@Produces(MediaType.TEXT_PLAIN)
public String getThings() throws IOException {
return "resource response";
}
}The SpringMVC implementation:
public class SimpleController {
@RequestMapping(value = "/get/things", method = RequestMethod.GET, produces=MediaType.TEXT_PLAIN)
@ResponseBody
public String getThings() throws IOException {
return "controller response";
}
}Both are fairly similar. Not too bad. Now let’s look at the tests.
The Jersey Test:
public class SimpleTest extends JerseyTest {
@Override
protected Application configure() {
return new ResourceConfig(SimpleResource.class);
}
@Test
public void test() {
String response = target("/get/things").request().get(String.class);
assertEquals("resource response", response);
}
}The SpringMVC Test:
public class SimpleControllerTest {
@Test
public void simple() throws Exception {
standaloneSetup(new Controller(mockedService)).build()
.perform(get("/get/things").accept(MediaType.TEXT_PLAIN))
.andExpect(status().isOk())
.andExpect(content().contentType("text/plain"))
.andExpect(content().string("controller response"));
}
}Both testing frameworks will allow you to build a very detailed request that is sent into the application using REST. We can set the HTTP method, the path, and headers.
The difference between these two examples is that SpringMVC has created an entire framework that will inspect the response. The Jersey testing framework will allow you to get the response body. The interesting part about the Jersey testing framework is that it was really created just to test the framework internally:
Jersey Test Framework originated as an internal tool used for verifying the correct implementation of server-side components
What we lack here that is possible with the SpringMVC framework is the full ability to assert the response. It’s also interesting that the top stack overflow question: “Unit testing jersey Restful Services” has the top answer being to use RestAssured (A generic API testing framework). Jersey isn’t a bad project. It’s really nice and very fast. My concern is that I am limited in verifying how it will work using fast integration tests.
Ok…. So Who Cares!?! It’s Just testing!
Automated testing is important. If don’t agree or hesitate to agree, then I’ve already lost my case. When I have brought in a new framework, I have three options when using it:
- Let’s verify how it works through integration testing.
- Let’s open up the source code and read through it.
- Let’s tell ourselves after it’s in production: “Other people use it”, “It seemed fine.”, “That’s what we pay our QA folks for.”, “I saw it on [hacker news]/[Some conference]/[youtube] and it should work fine.”
I think option one is the best. It provides a safety net for upgrades, understanding the framework (and your code). It safely allows other people to transition onto your team and guides them in how the application works without weeks/months/years of understanding.
Option two is valiant but many times you want the framework to solve a boilerplate or difficult problem for you. So the thought of understanding how this framework handles connection pooling or SSL or whatever gets you confused. If you are lucky enough to have a core contributor to the project on your team then that is great, but your bus factor is 1.
The last option is dumb. I’m not gonna sugar-coat this bad boy. The probability of failure goes up and what’s worse is that you will find it late in your project. I don’t ever want to work on a project that doesn’t have tests. I’m not a QA nut, I just don’t want to do support!